Advanced Ad Analytics and Tracking Implementation
Executive Summary
A resilient analytics stack unifies client and server signals to produce trustworthy revenue, performance, and UX insights. This guide provides a practical blueprint for taxonomy, collection, warehousing, reporting, and experimentation that respects privacy and scales with your business.
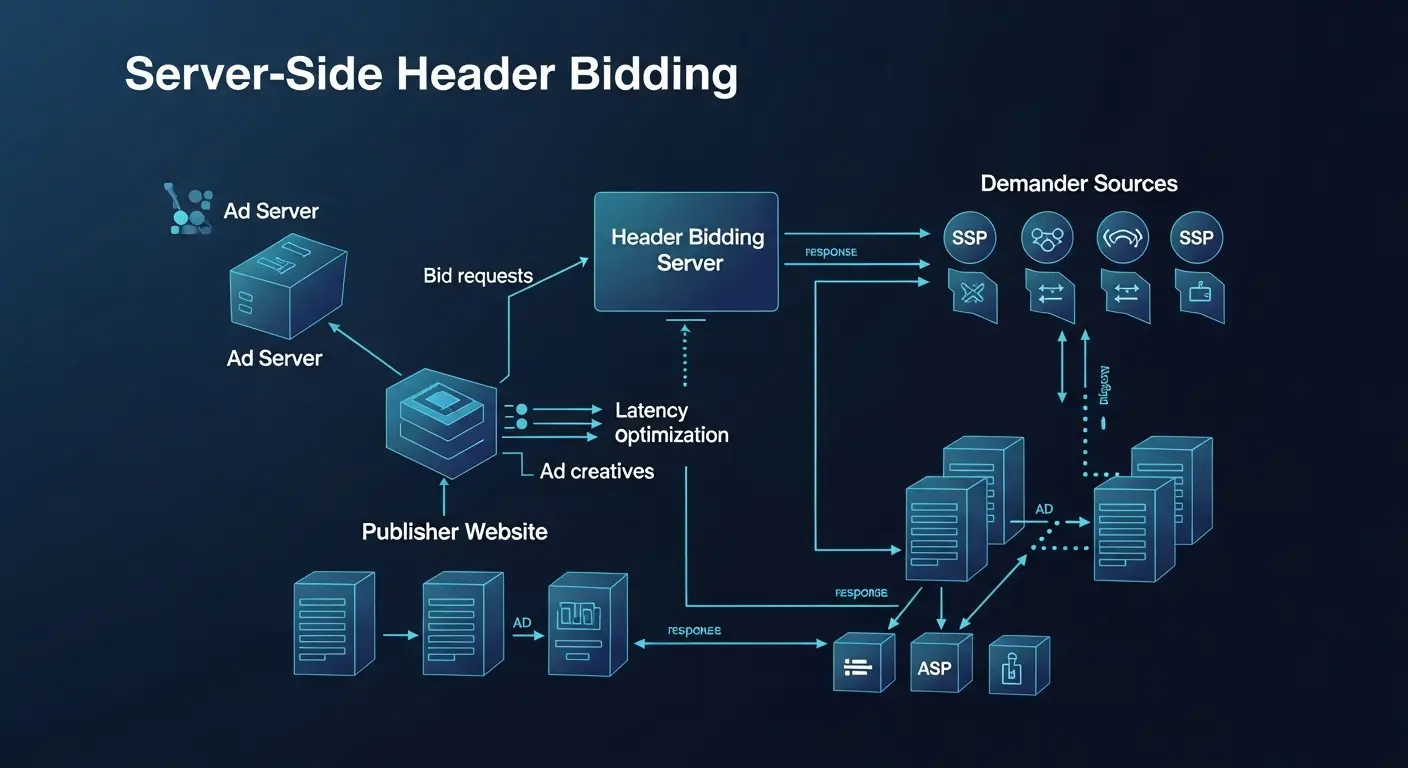
1) Measurement Architecture
- Client Events: Player/ad SDK events (impression, quartiles, clicks), viewability, errors, and UX signals.
- Server Collectors: Server-to-server impressions, revenue beacons, and batch partner reports.
- Data Warehouse: Central store for fact tables (impressions, revenue, sessions) and dimension tables (placements, partners, devices, geo).
- BI and Activation: Dashboards, alerts, and feedback loops to pricing, floors, and ad rules.
2) Event Taxonomy and IDs
- Core Events: ad_request, bid, auction_win, impression, viewable_impression, click, quartile_started/25/50/75/100, error.
- Revenue Events: line-item revenue, estimated bid revenue, sponsorships, and make-goods.
- Identity: request_id, auction_id, ad_unit_id, content_id, session_id, and anonymous user_id (hashed, consented where applicable).
- Context: page_url, referrer, device, app/web, player_version, network quality, and consent state.
3) Data Quality and Reliability
- Deduplication: Prioritize server beacons; reconcile client vs server using id pairs and time windows.
- Sampling and Rate Limits: Establish predictable sampling where unavoidable; annotate sample rates.
- Clock and Time Zones: Normalize to UTC; store local offsets for reporting.
- Bot/IVT Filtering: Apply multilayer rules; keep a quarantined table for investigation.
4) Privacy and Consent
- Consent Gating: Only send identifiers and personalization flags when consent allows; propagate consent strings in event payloads.
- Minimization: Drop PII at source; encrypt sensitive attributes in transit and at rest.
- Retention: Align data retention windows with policy; automate deletion for erasure requests.
5) Warehouse Schema Pattern
- Facts: fact_impressions, fact_revenue, fact_sessions, fact_content.
- Dimensions: dim_time, dim_partner, dim_ad_unit, dim_geo, dim_device, dim_content, dim_consent.
- Surrogate Keys: Use stable IDs; avoid joining on free text strings.
- Slowly Changing Dimensions: Track versioned partner mappings and line-item hierarchies.
6) Dashboards and KPIs
- Revenue: RPM per session, per page, per minute watched (video), and by placement.
- Demand Health: Fill rate, win rate, bid density, timeout losses, and floor impact.
- Quality: Viewability, completion rate (video), error rate, and Core Web Vitals correlations.
- Audience: New vs returning, geo/device mix, consent opt-in rate and revenue mix.
7) Attribution and Experiments
- Attribution Windows: Define lookback for impression → click → conversion; support multi-touch where relevant.
- Test Design: A/B with guardrails—sample ratio mismatch checks, sequential testing controls, and power analysis.
- Experiment Readouts: Lift with confidence intervals; segment by device/geo/placement.
8) Alerting and Operations
- Alerts: Anomaly detection on RPM, fill, error rate, and demand partner contributions.
- Runbooks: Clear remediation steps for timeouts, broken creatives, and consent propagation failures.
- SLIs/SLOs: Define freshness, completeness, and latency targets for data pipelines.
9) Implementation Steps
- Define taxonomy and IDs; instrument client events and server collectors in parallel.
- Set up pipelines to the warehouse; build core models and sanity checks.
- Launch initial dashboards and alerting; iterate on KPIs with stakeholders.
- Roll out experimentation framework and embed analytics into weekly business reviews.
Want an expert review of your analytics stack? Request an analytics implementation audit.